Old code never dies: why legacy software is often safer than new code
Show an engineer a twenty-year-old codebase and the reflex is often immediate: this is a liability waiting to explode. Old equals dangerous, new equals safe. It is one of those assumptions so widely shared in software development that it barely registers as an assumption at all, until something breaks at scale and the story becomes less comfortable. The reality is more humbling than the slogan.
The hidden curriculum inside old software
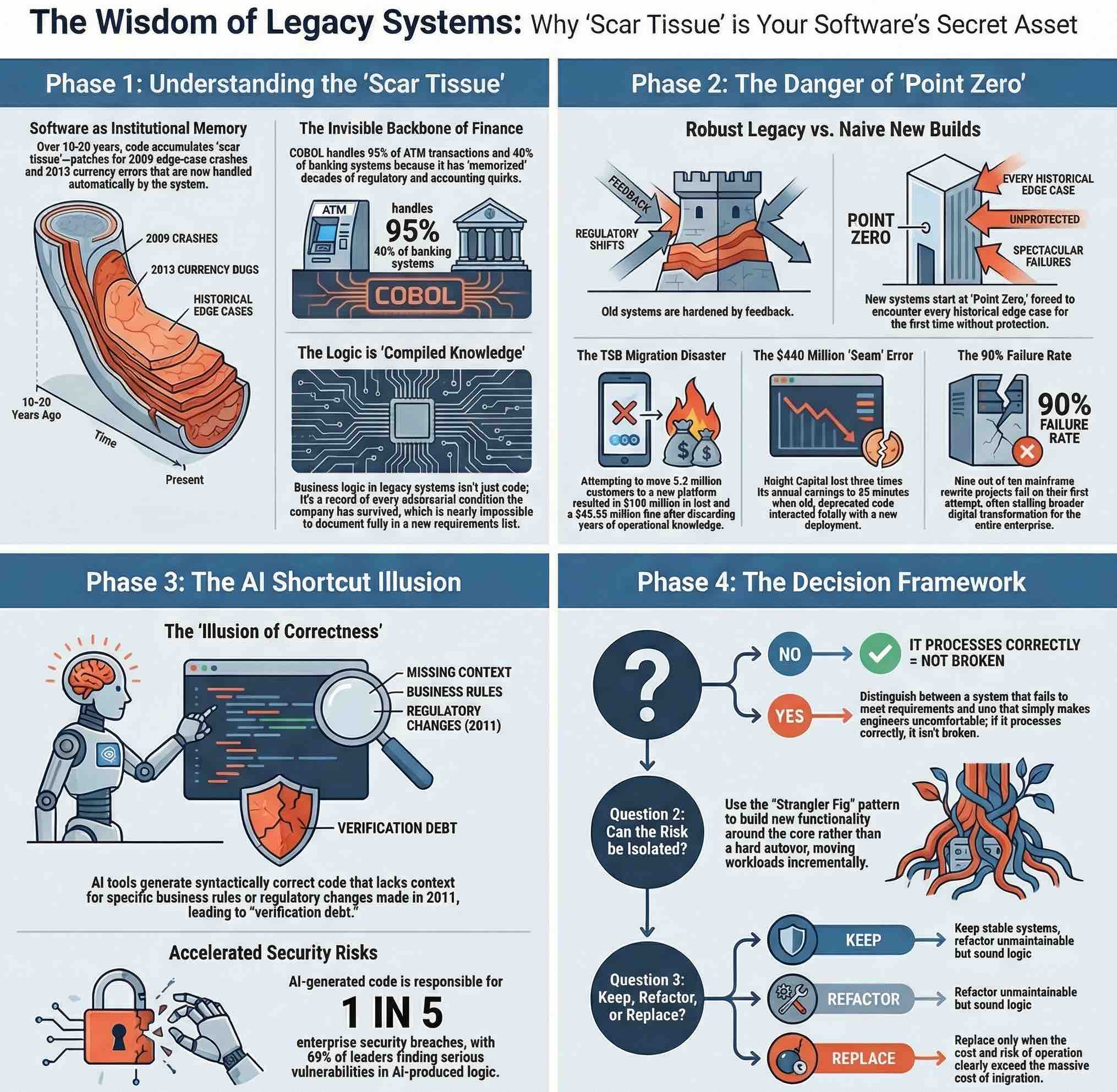
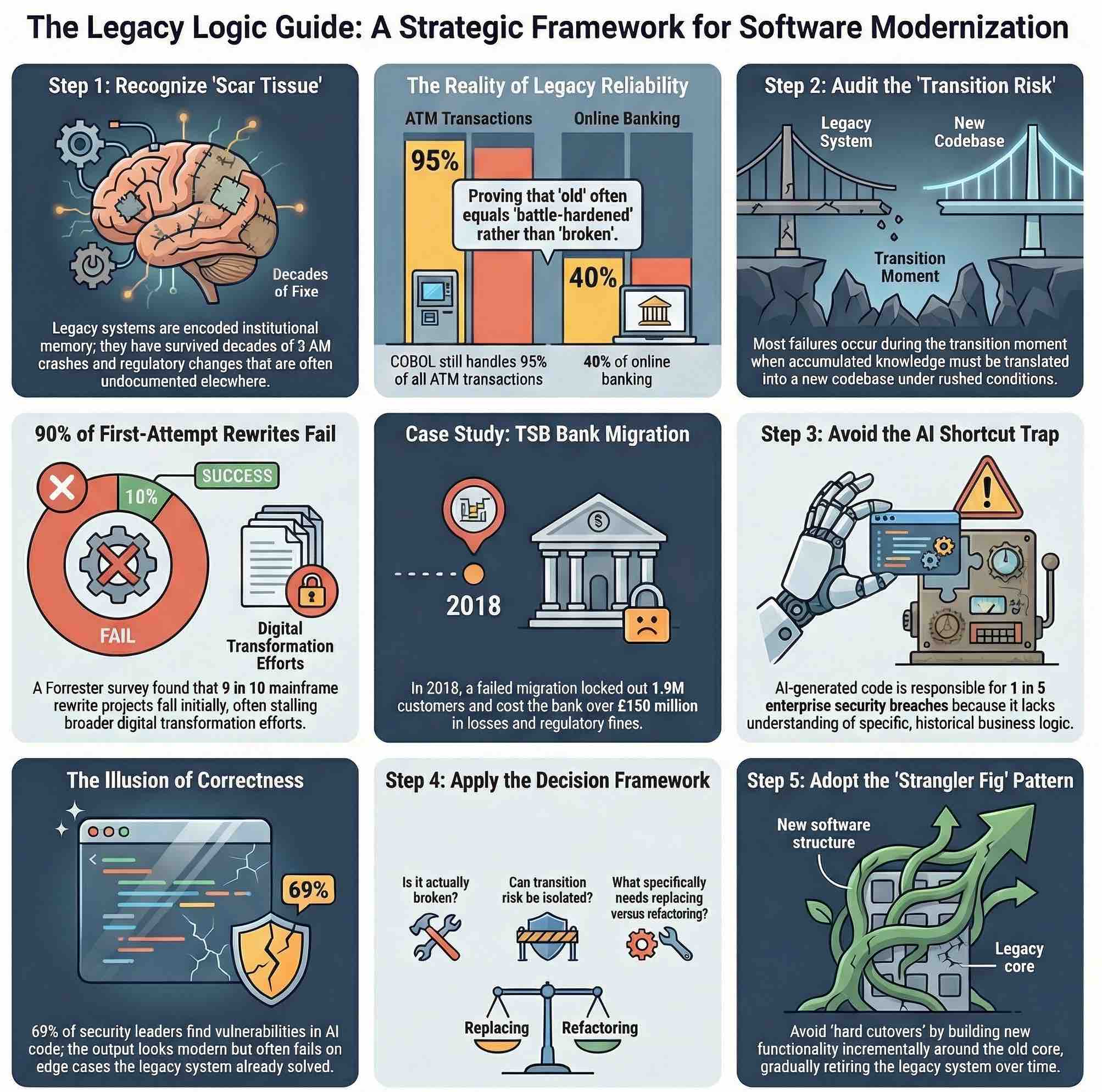
When a piece of software has been running in production for ten, fifteen, or twenty years, something important happens to it beyond simple aging. It accumulates scar tissue. Every edge case that crashed it at 3 AM on a Sunday in 2009 was eventually handled. Every currency formatting quirk that caused a reconciliation error in 2013 was patched, documented in a comment nobody reads, and quietly forgotten. The system knows things its authors no longer remember writing.
IBM notes that COBOL still underpins more than 40% of online banking systems and handles 95% of ATM transactions. Not because IT departments are lazy, or afraid of change, but because those systems have been refined through decades of real-world financial transactions, regulatory changes, and accounting edge cases that are almost impossible to fully enumerate in a requirements document. The business logic encoded in them is not just logic; it is institutional memory, compiled. When a bank says it “relies on legacy COBOL”, it is often not saying it lacks the budget to modernize. It is saying that it fears losing knowledge it cannot afford to lose.
The same dynamic appears in critical infrastructure. In January 2023, the FAA’s NOTAM
system, the database that issues notices to pilots about hazards and changes in airspace,
failed catastrophically
after a contractor accidentally deleted files while working on a database synchronization
task. The preliminary investigation found no cyberattack, no malicious intent, just a human
error made while touching a system whose complexity had grown to the point where a single
maintenance operation could bring down air traffic across the United States. The irony is
sharp: the very age and complexity of the system was both a risk factor and a signal of how
much depended on it continuing to work.
Mature systems are not just old code. They are the encoded result of years of operational feedback, adversarial conditions, regulatory pressure, and human correction. A new system, freshly written and cleanly architected, starts from zero. It will encounter all those edge cases for the first time.
When rewrites go wrong, they go spectacularly wrong
The failure mode of an aggressive rewrite is not subtle. It tends to be dramatic, expensive, and visible precisely because the stakes involved in replacing a core system are so high that the consequences of failure cascade across everything connected to it.
TSB Bank’s migration disaster is perhaps the most instructive recent example. In April 2018, the bank moved its 5.2 million customers from its legacy platform, inherited from Lloyds Banking Group, to a new system developed by its Spanish parent Sabadell. The goal was autonomy and cost savings. The result was that 1.9 million customers were locked out of their accounts, digital banking collapsed, branch systems failed, and payment transactions broke down. TSB reported a loss of £105 million in the first half of 2018. It was later fined £48.65 million by UK regulators. The migration had not simply replaced an old system. It had discarded years of operational knowledge about how TSB’s specific customer accounts, products, and edge cases actually behaved, and tried to reconstruct that knowledge from scratch under time pressure.
Knight Capital Group offers a different but equally instructive case. In August 2012, the firm deployed new trading code to its servers, but a technician failed to update one of eight machines. That single server, running old code that had been deprecated years earlier, began executing a strategy called Power Peg without the feedback loop that was supposed to stop it. In 45 minutes, Knight Capital lost $440 million, roughly three times its annual earnings. The immediate cause was a deployment error, but the real problem ran deeper: old code had been left in production, coexisting with new code in ways nobody had fully mapped. The rewrite had been partial, and the seam between old and new was fatal.
These failures point to the same problem. The risk is rarely the old system itself. It is the transition: the moment when the accumulated operational knowledge of the legacy system has to be translated into a new codebase under conditions that are almost always rushed, and where the test coverage of real-world edge cases is necessarily incomplete. A Forrester survey commissioned by Rocket Software found that nine in ten mainframe rewrite projects fail on their first attempt, and that more than half of those failures stalled broader digital transformation initiatives. Nine out of ten.
The AI shortcut that is not a shortcut
AI-assisted code generation now arrives as the tempting shortcut. The pitch is simple: AI tools can write code faster than humans, translate legacy languages into modern ones, and generate boilerplate that would otherwise consume months of engineering time. For organizations looking to finally escape their COBOL dependencies, that sounds less like a tool and more like an exit ramp.
It does not work that way. Research published in early 2026 found that AI-generated code is now responsible for one in five enterprise security breaches, with 69% of security leaders having found serious vulnerabilities in code produced by AI tools. A separate survey found that nearly half of developers fail to review AI-generated code before deploying it. The Black Duck CEO Jason Schmitt described the dynamic precisely: “The real risk of AI-generated code isn’t obvious breakage; it’s the illusion of correctness. Code that looks polished can still conceal serious security flaws, and developers are increasingly trusting it.”
That confidence gap is not limited to code; it is part of the broader problem of trusting AI.
An AI model trained on public code repositories does not understand the specific business logic of a banking core system. It does not know which validation rules were added after a specific regulatory change in 2011, or why a particular rounding function works the way it does, or what happens to transaction reconciliation if a certain field is null in a very specific edge case involving a product that was discontinued eight years ago but whose accounts still exist. It can write syntactically correct, stylistically modern code that passes all the tests you thought to write and fails on the cases you did not think to test, because the legacy system had encountered those cases and you had not.
Separate testing reported by ITPro found that only 55% of AI-generated code was free of known vulnerabilities across more than 100 models and 80 coding tasks. Another ITPro report on Sonar’s survey showed that many developers still fail to review AI output even when they do not fully trust it, creating what Sonar called “verification debt.” Speed without scrutiny is not productivity; it is technical debt arriving faster.
AI-assisted development has genuine value. In high-stakes environments, though, it needs clear governance, mandatory review, and a realistic understanding of where it helps versus where it merely sounds convincing. The incremental rewrite approach familiar from Rust adoption offers a useful analogy: identify a bug-prone component, rewrite it in isolation with clear interfaces, verify it against the original behavior, and move on. Do not rewrite everything at once.
A framework for deciding what to do next
So what should an organization do with a legacy system? Start with three questions.
First: is the system actually broken, or does it just look old? There is a significant difference between a system that is failing to meet current requirements and one that simply runs on infrastructure that makes engineers uncomfortable. COBOL that processes transactions correctly and reliably is not broken. An interface that frustrates users or an architecture that cannot integrate with modern APIs may be a problem worth solving without touching the core logic at all.
Second: if the system genuinely cannot meet current needs, can the transition risk be isolated? The strangler fig pattern (new functionality built around the old system incrementally while the legacy core is gradually retired) is often more appropriate than a hard cutover. TSB attempted something close to a hard cutover, with known consequences. Organizations that have modernized more successfully tend to have done it in phases, maintaining parallel systems, validating behavior against the old codebase, and moving customers or workloads incrementally.
Third: what should be kept, what should be refactored, and what really needs replacing? Keep systems that are stable, well-understood, and functionally correct, even if they look old. Isolate systems that carry security or compliance risk but cannot yet be replaced, wrapping them in controlled interfaces that limit their exposure surface. Refactor components where the logic is sound but the implementation has become unmaintainable. Replace only when the cost of continued operation, including risk, clearly exceeds the cost and risk of migration, and even then, plan for the transition to take longer and cost more than estimated.
The CrowdStrike incident of July 2024 is a useful reminder that new software can fail just as catastrophically as old software, and that the interconnectedness of modern systems means that a single faulty update can ground airlines, block banking transactions, and disrupt broadcasts across multiple continents simultaneously. The issue was not age, but aggressive deployment into systems that had no fallback when the update failed.
Across all these cases, age is mostly a distraction. What matters is operational understanding, careful change management, and testing against real-world conditions. Well-understood old software is often safer than new software that has not yet met the world. Modernization matters when it solves a real problem, not when it merely satisfies an aesthetic one. The job is to understand what you have, be honest about what it can and cannot do, and change it with the care its role actually demands.
Anything less is not engineering. It is just renovation theater.