OSINT, the secret weapon of 4channers
“A good rule of the Internet is to never tell 4chan something is impossible.”
What happened between Shia LaBeouf and some users of 4chan?
The news now is fairly well known, but I try to summarize the main points of a story that shows that nothing is impossible, when you properly use sources freely available on internet (OSINT), and a good dose of cleverness.
Premise
Shia LaBeouf decided to launch a protest against Trump: an art exhibition called “He will not divide us”, which consists of a live video along all the duration of the Trump presidency.

from pagesix.com
However, during the event, some users of 4Chan (pro Trump) go on the exibition site and starts a protest. The protest ends in a brawl.
https://www.youtube.com/watch?v=2tYVrFDxcDY
Capture the Flag!
https://www.youtube.com/watch?v=W6uGP8hHwrQ
After continuous provocations, and the complaints from local residents, the live video is closed and LaBeouf decides to move the video transmission into a secret location: now only shows a flag waving in the wind with the catchphrase “He will not divide us“.
At this point the 4chan’s trolls starts an investigation using the free resources available on the internet.
First of all, observing the wind, they speculate that the flag could be located in Salt Lake.
But after LaBeouf was sighted in Greeneville, and after controlling wind directions and times of sunset and sunrise, it is determined that in fact is located in Greeneville.
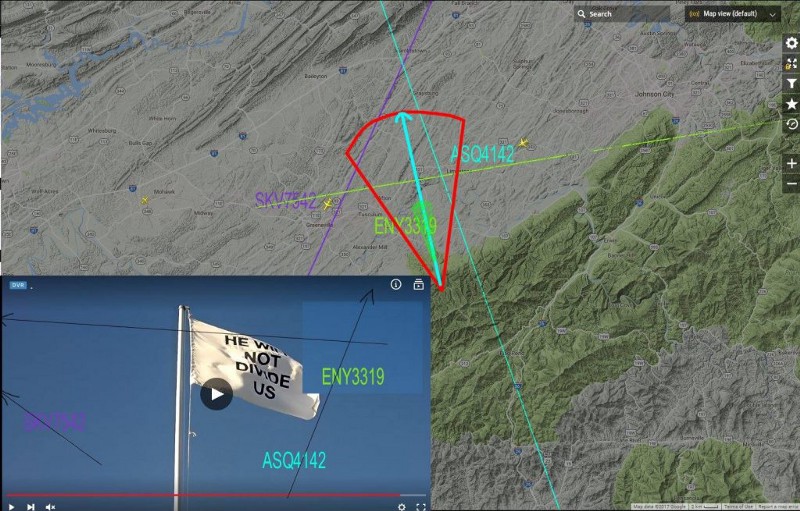
The area is large, and to narrow it the “investigators” starts studing the trails left by aircraft: crossing the routes of three aircrafts, they get a more defined area.

At this point, using the positions of the stars visible at night, they get a small area of few square kilometers, so a member of 4Chan living in this area decides to go out with his truck and sound the horn to see if at some point it feels in the live video.

In minutes, the flag is found, lowered and removed, and in its place appears a Trump “Make America Great Again” hat and a Pepe the Frog t-shirt.
The next morning Shia LaBeouf, defeated, switch off the video.
The flag now rests in the home of a 4chan user:

Here the original article on Heast.com:
But, what is OSINT?
From Wikipedia:
Open-source intelligence (OSINT) is intelligence collected from publicly available sources.
OSINT includes all publicly accessible sources of information, such as:
- Media : newspapers, magazines, radio, television, and computer-based information.
- Web-based communities and user-generated content : social-networking sites, video sharing sites, wikis, blogs, and folksonomies.
- Public data : government reports, official data such as budgets, demographics, hearings, legislative debates, press conferences, speeches, marine and aeronautical safety warnings, environmental impact statements and contract awards.
- Observation and reporting : amateur airplane spotters, radio monitors and satellite observers among many others have provided significant information not otherwise available. The availability of worldwide satellite photography, often of high resolution, on the Web (e.g., Google Earth) has expanded open-source capabilities into areas formerly available only to major intelligence services.
- Professional and academic (including grey literature) : conferences, symposia, professional associations, academic papers, and subject matter experts.
- Most information has geospatial dimensions, but many often overlook the geospatial side of OSINT : not all open-source data is unstructured text. Examples of geospatial open source include maps, atlases, gazetteers, port plans, gravity data, aeronautical data, navigation data, geodetic data, human terrain data (cultural and economic), environmental data, commercial imagery, LIDAR, hyper and multi-spectral data, airborne imagery, geo-names, geo-features, urban terrain, vertical obstruction data, boundary marker data, geospatial mashups, spatial databases, and web services. Most of the geospatial data mentioned above is integrated, analyzed, and syndicated using geospatial software like a Geographic Information System (GIS) not a browser per se .
- Deep Web: Information hidden from the Surface web currently estimated to represent the majority of content on the Web.