Why prudence still wins in high-stakes technology
This morning, while running with AirPods in, I listened to StoryTech, Fjona Cakalli’s podcast about the less visible side of technology. In one episode on major tech failures, she used two labels that stayed with me: the “Disciples of Chaos” and the “Guardians of Prudence.” One camp treats speed, novelty, and disruption as goods in themselves. The other treats reliability as a hard-won asset and asks for strong evidence before replacing what already works.
Both instincts contain something useful, and both can become dangerous. That tension shows up in engineering teams, product decisions, infrastructure planning, and security operations. It matters even more when the consequences are not just a rough release, but service outages, financial losses, or security failures.
That is the lens I want to use here: not to defend legacy systems by default, and not to romanticize disruption, but to look at a few cases where the balance between ambition and restraint was judged well or badly.

When visionaries crash: the seduction of the impossible
The Apple Newton remains one of the clearest examples of a product that was directionally right and commercially premature. Released in 1993, it tried to put a digital assistant in people’s hands years before the market, the interface patterns, and the supporting hardware were ready. In retrospect, the core idea was sound.

The execution was not. Handwriting recognition, the Newton’s signature feature, became its weakness: unreliable enough to turn a serious product into a punchline. The device was bulky, expensive, and asked users to tolerate too much friction. Apple did not fail because the ambition was wrong. It failed because the product reached the market before the experience was good enough.
The Concorde tells a similar story at a much larger scale. For almost thirty years, British Airways and Air France operated the best-known supersonic passenger aircraft ever built. It was technically remarkable, and its economic limits were obvious from the start: high fuel burn, route restrictions caused by the sonic boom, extreme operating costs, and a customer base narrow enough to keep the model exclusive rather than scalable. The aircraft worked. The business case never really did.

The common mistake in both cases was not innovation itself. It was assuming that technical brilliance would somehow make the surrounding constraints disappear.
The stubborn survivors: on the dignity of the boring
While the Newton was becoming a punchline and the Concorde was retiring without a successor, something less photogenic was happening in data centers around the world. COBOL, a programming language that was already considered old-fashioned in the 1980s, was quietly becoming indispensable.
Today, COBOL still sits under a large share of financial infrastructure. IBM says it supports more than 40% of online banking systems, 80% of in-person credit card transactions, and 95% of ATM transactions. Systems built on IBM midrange platforms and mainframes still run ERP, accounting, logistics, and banking workloads across thousands of organizations. That is not just a story about inertia. It is also a story about reliability.
TSB Bank learned the cost of underestimating that reliability in 2018. During its migration of 5.2 million customers to a new platform, large parts of its banking services failed. Regulators later confirmed that the outage affected all branches and a significant proportion of customers, and the bank was eventually fined £48.65 million for operational resilience failings. The old platform had limits, but the migration failed because the replacement program was not controlled well enough.
This is the part that debates about legacy technology often flatten: old systems do not just contain code. They contain operational knowledge. Over time they absorb exceptions, regulatory changes, obscure edge cases, and business rules that are easy to dismiss and hard to rebuild. That is one reason rewrites fail so often. In a Forrester survey commissioned by Rocket Software, nine out of ten mainframe rewrite projects failed on the first attempt.
IBM recognized the value of continuity much earlier. When it launched the System/360 in 1964, it made compatibility a core design principle: customers could upgrade within the family without rewriting their software. That was not conservatism for its own sake. It was an engineering decision that reduced risk and preserved value.
The cybersecurity front: where recklessness becomes systemic risk
The tension between innovation and prudence becomes sharper in cybersecurity, where bad engineering decisions can propagate at machine speed.
On 19 July 2024, CrowdStrike pushed a content update to its Falcon sensor that caused more than 8.5 million Windows systems to crash worldwide. Airlines stopped flights, hospitals reverted to manual procedures, and the estimated losses exceeded $5 billion. It was not an attack. It was a faulty update distributed at enormous scale by a security vendor with deep system-level access.
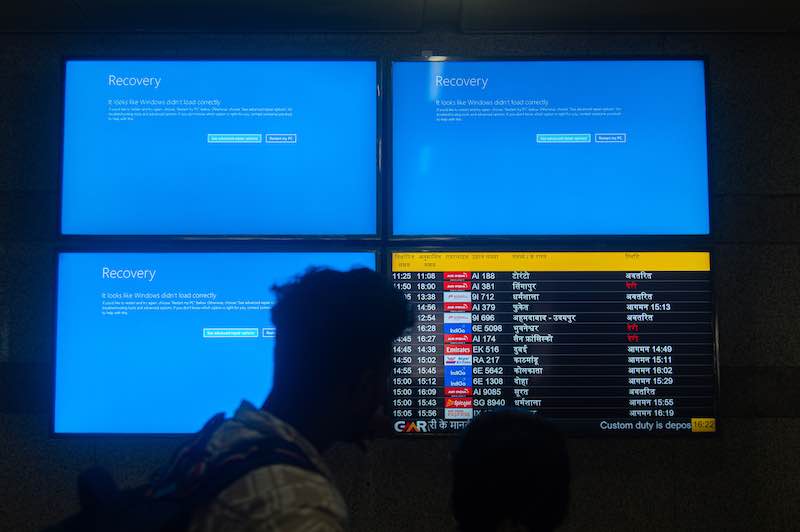
The lesson was not only about testing. It was also about concentration risk. When one security product sits close to the kernel on millions of endpoints, efficiency and exposure grow together. A similar point emerged in Cloudflare’s broad outage of June 2025, when the failure of a critical third-party dependency took Workers KV offline and disrupted multiple Cloudflare services at once. Centralized platforms simplify operations right up to the moment they fail all at once.
The broader culture behind this is familiar. The phrase “move fast and break things” became shorthand for a style of software development that prizes speed over resilience. In practice, that tradeoff leaves exposed systems everywhere. Recent campaigns against Microsoft SharePoint in 2025 and Ivanti edge devices in 2023 show how quickly widely deployed enterprise software becomes a large attack surface when security and change control fall behind.
Legacy platforms complicate the picture. They are sometimes harder to hit with commodity tooling because the attack surface is narrower, the environments are more specialized, and the skills required to compromise them are less common. But that should not be mistaken for good security. As Tripwire notes in its review of security risks facing COBOL mainframes, many of these systems still depend on weak access controls, old protocols such as FTP and TN3270, and patching practices that do not match modern threat conditions. Obscurity can reduce opportunistic attacks; it does not remove structural weaknesses.
There is also the quieter problem of automation used without enough supervision. In one incident I described previously, an automated threat intelligence pipeline at a large Italian company quarantined critical Windows files on more than two thousand endpoints after a bad external feed entry combined with an API failure and poor error handling. No attacker needed to do anything. The process was fragile enough on its own.
Finding balance: the mature engineering position
Neither camp is fully right. The more useful position is also the more demanding one.
Innovation matters because systems that never change eventually become liabilities. Some capabilities simply cannot be added by preserving everything as it is. The Newton does not show that new ideas are a mistake; it shows that timing, execution, and readiness matter as much as vision.
Prudence matters because old systems often embody knowledge that teams underestimate until they try to replace it. A careful modernization strategy does not mean refusing change. It means making smaller moves, preserving a stable core where possible, validating new components against known behavior, and treating migration risk as a first-class engineering problem.
In security, that usually means combining a conservative core with faster layers around it. I still find the framing from the Cathedral and the Bazaar useful here: some parts of a system should evolve quickly, but the layers that can take down entire fleets or critical services need slower rollout, narrower blast radius, and better validation.
So the real question is not whether innovation is good and caution is bad, or the reverse. It is simpler than that: for this component, in this context, what is the cost of being wrong? If the answer is a minor feature regression, the appetite for experimentation can be high. If the answer is grounded flights, inaccessible patient records, or a multi-billion-dollar outage, the standard should be very different.
That is the tension worth preserving. The Concorde showed that technical excellence does not guarantee viability. COBOL shows that unfashionable technology can remain indispensable for decades. Good engineering judgment is knowing when to push, when to preserve, and when the transition itself is the riskiest part of the system.